Master Thesis
Sep. 2021 - Sep. 2022
Back to engineering page
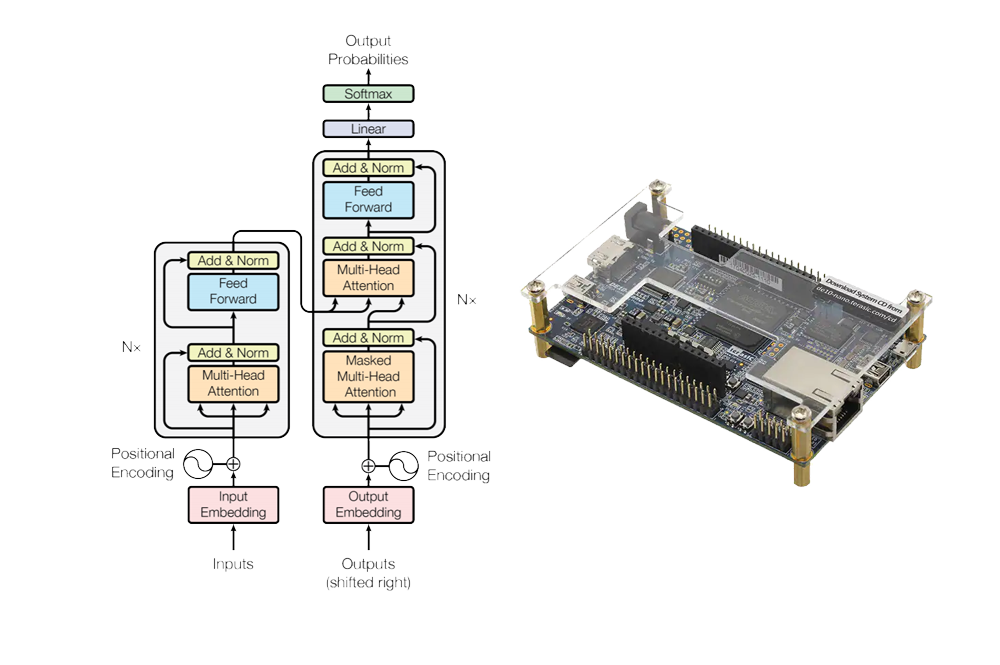 My Master thesis was about the mapping and acceleration of a Transformer (the kind of neural network underlying chatGPT or Dall-E for example) onto an embedded platform: the DE10-Nano. I realized this work with my co-student Antoine Vanden Clooster.
To summarize it, here is the abstract of our paper:
My Master thesis was about the mapping and acceleration of a Transformer (the kind of neural network underlying chatGPT or Dall-E for example) onto an embedded platform: the DE10-Nano. I realized this work with my co-student Antoine Vanden Clooster.
To summarize it, here is the abstract of our paper:
Today embedded devices are all around us. With the addition of Machine Learning (ML) in such devices, a wide range of applications is possible. These platforms however generate a great amount of data to be processed. A current challenge in IT consists of reducing the data circulating on communication networks. Indeed these grow year after year and represent a non-negligble worldwide energy consumption. Edge computing proposes to tackle this problem by handling data at the edge without resorting to computing servers. The research for efficient hardware accelerators is a good lead in this direction.
The Transformer network is a recent architecture that could handle multiple tasks at once, reducing the need for different model-targetted accelerators and co-processors. The multimodal training possibility of this architecture, coupled with the current need for smart sensors capable of handling data by themselves in an acceptable latency are the reasons that motivate this work. This thesis aims indeed at deploying a Multi-Head Attention (MHA) block from the Transformer architecture on the DE10-Nano embedded device. After having identified the bottlenecks of the MHA, a hardware accelerator is proposed to tackle them.
From an initial Software Floating-Point (FP) implementation taking 121.7 ms for one inference, we go to an accelerated quantized Software-Hardware co-designed system taking 13.29 ms on the same input, accelerating the process by 89%. A software-only integer implementation is also presented, reducing the initial time by 79.73% and thus demonstrating the value of quantization.
If you are interested in the work we achieved, it can be accessed freely at this address.